Statistics for Experimentation: Controlled Experiments
Suppose you are presented with the graph (I) on the left:
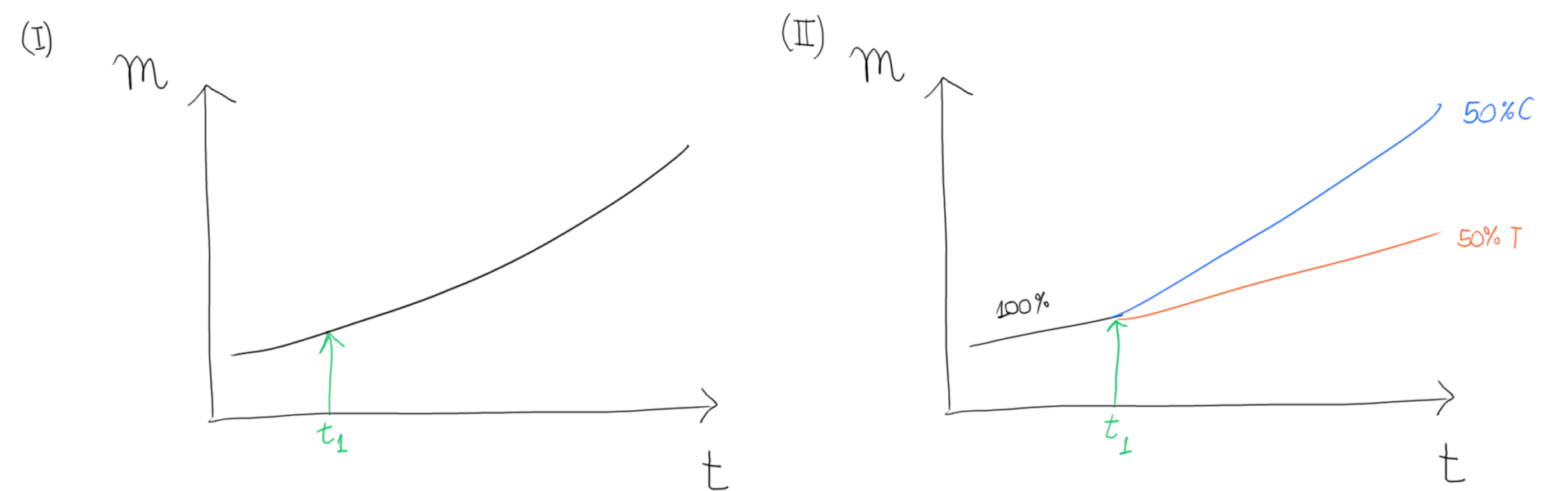
This graph plots the evolution of some metric m over time t, showing an upward trend. Suppose an intervention was made at some point t = t1, as shown in green. Which of the following conclusions can we arrive at by looking solely at the (I) graph?
1A. The intervention had a positive effect on the metric m.
1B. The intervention had a neutral effect on the metric m.
1C. The intervention had a negative effect on the metric m.
1D. I don't know.
Now look at the graph (II) on the right. It displays a similar picture, but this time an experiment was set up.
Up to some point in time t = t1, the metric was allowed to progress without intervention, the same as before. After that, the sampling was split 50%/50% between two groups and the metric m was once again measured, but now for each individual partition.
Consider that no intervention was performed on the C (or control) partition. This represents the null hypothesis, which attempts to answer the “what if we do nothing?” question. Thus, the intervention was solely performed on the T (or treatment) partition. This graph now compares how both groups have performed over time with regard to the same metric m.
Which of the following conclusions can we arrive at by looking at the (II) graph?
2A. The intervention had a positive effect on the metric m.
2B. The intervention had a neutral effect on the metric m.
2C. The intervention had a negative effect on the metric m.
2D. I don't know.
I argue that the conclusion for the first question asked should be at most 1D: “I don't know”. The reason being that there's no way to account for the contribution of external factors -- such as seasonal effects, long-term trends and random noise -- to the final result. We can't possibly know for sure that the movement we observe is mainly due to the intervention performed.
We can fool ourselves we are doing something useful -- and we often do --, while in reality the observed movement wasn't due to a factor we had direct control over.
On the other hand, consider the second setup: we can be fairly certain that the intervention had a negative effect on the outcome, as measured by the metric m.
Why can we be so sure this time? Because any long-term trend or seasonal effect would affect both control and treatment equally! In statistical terms, we are controlling for those effects, meaning that we are (hopefully) accounting for and excluding their contribution from the final analysis.
A second question can be: Why does the split need to be 50%/50%? Why can't we expose more samples to the treatment group instead? The reason is being able to control for noise. If one of the groups is substantially larger than the other -- say, in a 90%/10% split, the treatment group is 9x larger than control --, random noise will have a much more pronounced effect on the smaller group, which will limit the statistical significance of the comparison.
By and large, the point of experimentation is to have two configurations as similar as possible and only change one thing. Assuming that: a) there is no bias in how samples were put into each group; and b) that both groups are equally exposed to the remaining effects; one can be fairly certain that all factors other than the one thing the intervention is about were controlled for, meaning that we are in fact measuring the impact of the intervention alone.